让不懂建站的用户快速建站,让会建站的提高建站效率!


DeepSeek开源新模子:用视觉模式收场高下文压缩。
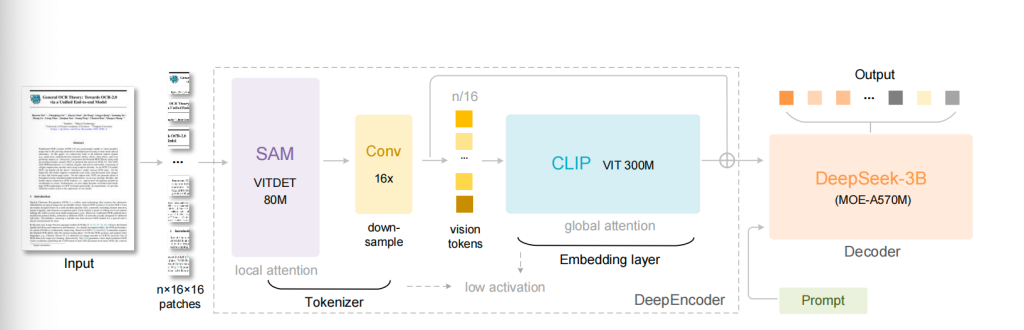
10月20日,DeepSeek晓示开源最新大模子DeepSeek-OCR。所谓的OCR,据DeepSeek在论文中解释称,是通过光学2D映射压缩长高下文可行性的初步议论。DeepSeek-OCR由两部分组成:DeepEncoder和行动解码器的DeepSeek3B-MoE-A570M。DeepEncoder行动中枢引擎,筹画为在高分手率输入下保执低激活,同期收场高压缩比,以确保视觉tokens数目优化且可料理。
鄙俗而言,这是一种视觉-文本压缩范式,通过用少许的视觉token来示意正本需要巨额文本token的践诺,以此裁减大模子的揣摸支出。
据公布的论文名单走漏,该样式由DeepSeek三位议论员Haoran Wei、Yaofeng Sun、Yukun Li共同完成,但这三位中枢作家齐颇为低调,其中一作作家Haoran Wei曾在阶跃星辰责任过,曾主导开拓旨在收场“第二代 OCR”的GOT-OCR2.0系统。

DeepSeek-OCR的架构分为两部分。一是DeepEncoder,一个专为高压缩、高分手率文档处理筹画的视觉编码器;二是DeepSeek3B-MoE,一个轻量级搀和众人话语解码器。这款刚开源不久的新模子,发布后就得到国外科技媒体平时传诵,有网友盛赞:“这是AI的JPEG技术。”
前特斯拉AI总监、OpenAI创举成员安德烈·卡帕西(Andrej Karpathy)在酬酢媒体高度评价DeepSeek的新模子,他示意,我方稀疏心爱新的DeepSeek-OCR论文,“它是一个很好的OCR模子(可能比dots稍许差一丝),是的,数据集合等等,但岂论怎样齐不紧迫。对我来说更意义意义的部分(尤其是行动一个以揣摸机视觉为中枢,暂时伪装成当然话语的东说念主)是像素是否比文本更适配合为LLM的输入。行动输入,文本记号是否浮滥且灾祸。”
凭证他的遐想,好像统共LLM的输入齐只应该是图像。即即是纯文本践诺,也应该先渲染成图片再输入给模子,其中事理包括:信息压缩放置更高、像素更通用、撑执双向疑望力、可淘汰存在安全隐患的分词器(Tokenizer)。
特斯拉创举东说念主马斯克(Elon Musk)也现身驳倒区,并示意:“从永久来看,AI模子逾越99%的输入和输出齐将是光子,莫得其他任何东西不错领域化。”
知名科技媒体《麻省理工科技驳倒》解释称,DeepEncoder是通盘系统的要害所在。它的筹画方针在于,在处理高分手率输入图像的同期,保执较低的激活内存,并收场极高的压缩比。为达到这一方针,DeepEncoder会通两种进修的视觉模子架构:SAM(Segment Anything Model)和 CLIP(Contrastive Language–Image Pre-training)。前者以窗口疑望力机制(window attention)见长,擅所长理局部细节,组成编码器的前半部分;后者则依赖密集的全局疑望力机制(global attention),能够拿获举座学问信息。
《麻省理工科技驳倒》示意,除了文本识别性能,DeepSeek-OCR还具备较强的“深度领会”才略。这收货于其检会数据中包含了图表、化学分子式、几何图形等各样化的视觉践诺。因此,模子不仅能识别设施文本,还能对文档中镶嵌的复杂元素进行结构化领会。举例,它不错将论说中的图表调遣为表格数据,将化学文件中的分子式输出为SMILES要害,或领会几何图形中的线段联系。这种超过传统文本识别的才略,拓展了其在金融、科研、教授等专科领域的愚弄空间。
DeepSeek先容,实验标明,当文本tokens数目在视觉tokens的10倍以内(即压缩比<10×)时,模子可达到97%的OCR精度。即使在20×压缩比下,OCR精度仍保执在约60%。这为历史长高下文压缩和LLM中的挂牵淡忘机制等议论领域展示可不雅远景。
DeepSeek-OCR还初步考证高下文光学压缩的可行性,讲解模子不错从少许视觉tokens中有用解码逾越10倍数目的文本tokens。DeepSeek-OCR亦然一个高度实用的模子,可大领域坐褥预检会数据,“往时,咱们将进行数字-光学文本交错预检会、大海捞针测试等进一步评估,陆续鼓舞这一有远景的议论场地。”
据国外科技媒体分析,议论团队示意,在基准测试中,DeepSeek-OCR优于多个主流模子,且使用的视觉tokens数目少得多。此外,单张A100-40G GPU每天可生成逾越20万页的检会数据,可为大型话语模子和视觉-话语模子的开拓提供撑执。
前网易副总裁、杭州议论院实践院长汪源发文示意,DeepSeek-OCR模子是一个成心能“读懂”图片里笔墨的AI模子。但犀利的地方不是省略“识字”,是继承了一种相等新颖的想路:把笔墨当成图片来处理和压缩。
汪源以为,不错把它设想成一个超等高效的“视觉压缩器”,传统的AI模子是径直“读”文本,但 DeepSeek-OCR 是先“看”文本的图像,然后把一页文档的图片信息高度压缩成很少的视觉tokens。DeepSeek-OCR的才略强在能把一篇1000字的著述,压缩成100个视觉tokens。在十倍的压缩下,识别准确率不错达到96.5%。

股票配资平台-实盘配资平台交易流程与资金安全全解析提示:本文来自互联网,不代表本网站观点。